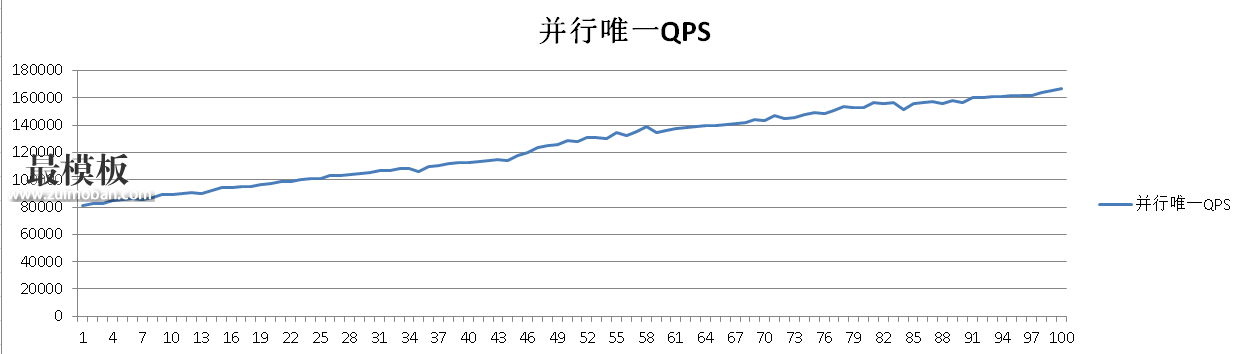
在没有唯一约束或者主键约束时,数据库是不保证唯一性的。那么有什么手段来保证呢? 方法 1. 串行操作,先查询,如果没有查到记录,则插入。这种方法效率非常低: 测试如下: postgres=# create table tbl(c1 text); CREATE TABLE postgres=# create index idx_c1 on tbl(c1); CREATE INDEX postgres=# create or replace function load(v_c1 text) returns void as $$ declare begin perform 1 from tbl where c1=v_c1 limit 1; if found then return; else insert into tbl(c1) values (v_c1); end if; end; $$ language plpgsql strict; CREATE FUNCTION 压测: vi test.sql \setrandom c1 1 50000 select load(:c1); pgbench -M prepared -n -r -P 1 -f test.sql -c 1 -j 1 -T 100 性能分析,由于以上方法只能在串行模式下保证C1字段的唯一性,如果是并行模式,无法保证唯一性。所以性能完全仰仗load函数的RT,有效插入性能差,无效插入则依赖查询的RT,性能相对较好。 在60秒的时候,数据已经满5万了,所以都变成了无效插入,即查询后直接return。 progress: 59.0 s, 375.0 tps, lat 2.673 ms stddev 1.113 progress: 60.0 s, 368.0 tps, lat 2.713 ms stddev 1.110 progress: 61.0 s, 5787.1 tps, lat 0.172 ms stddev 0.521 progress: 62.0 s, 12538.1 tps, lat 0.079 ms stddev 0.012 progress: 63.0 s, 12802.2 tps, lat 0.077 ms stddev 0.011 验证约束准确性: postgres=# select count(*),count(distinct c1) from tbl; count | count ---------+--------- 50000 | 50000 (1 row) 性能趋势: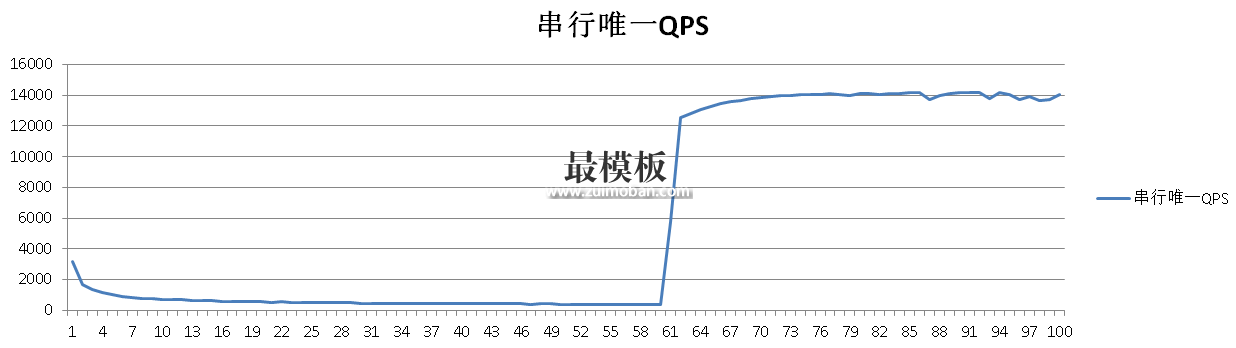 方法2. advisory lock和秒杀场景的方法一样(PostgreSQL秒杀一条记录能达到23万的qps。): http://blog.163.com/digoal@126/blog/static/16387704020158149538415/ 本例一样使用advisory lock,当锁冲突时,并行会话变串行会话,其他无冲突会话都是并行执行的。 我们来看看性能提升多少? postgres=# create or replace function load(v_c1 text) returns void as $$ declare begin perform 1 from tbl where c1=v_c1 limit 1; if found then return; end if; if ( pg_try_advisory_xact_lock(hashtext(v_c1)) ) then perform 1 from tbl where c1=v_c1 limit 1; if not found then insert into tbl(c1) values (v_c1); else return; end if; else return; end if; end; $$ language plpgsql strict; 压测500万唯一值。 vi test.sql \setrandom c1 1 5000000 select load(:c1); 52个并发: pgbench -M prepared -n -r -P 1 -f test.sql -c 52 -j 52 -T 100 越来越快,因为无效插入越来越多。如果全变成无效插入,理论上qps也是能达到20万以上的。 progress: 96.0 s, 161872.6 tps, lat 0.319 ms stddev 0.429 progress: 97.0 s, 161766.4 tps, lat 0.319 ms stddev 0.387 progress: 98.0 s, 164232.7 tps, lat 0.315 ms stddev 0.419 progress: 99.0 s, 165476.5 tps, lat 0.312 ms stddev 0.405 progress: 100.0 s, 166866.0 tps, lat 0.309 ms stddev 0.410 transaction type: Custom query scaling factor: 1 query mode: prepared number of clients: 52 number of threads: 52 duration: 100 s number of transactions actually processed: 12510348 latency average: 0.414 ms latency stddev: 0.450 ms tps = 125034.429736 (including connections establishing) tps = 125043.765999 (excluding connections establishing) statement latencies in milliseconds: 0.003204 \setrandom c1 1 5000000 0.410254 select load(:c1); 验证结果,并发唯一,bingo。 postgres=# select count(*),count(distinct c1) from tbl; count | count ---------+--------- 4593181 | 4593181 (1 row) 性能趋势:
应用场景举例比如 tbl (internal_id int serial8 primary key, nick_name text unique, ......) internal_id 对应的是内部使用的唯一ID nick_name 是用户的唯一ID,也是唯一的。 用户会输入一个nick_name,通过序列生成内部ID。 如果一开始就有这样的约束,问题就不存在。 但是当以前使用的数据没有加唯一约束,然后已经有重复值产生了。 现在想把唯一约束建立起来,首先要去重复,然后建立唯一约束。 在建立唯一约束前,如果用户还有数据不断录入,并且需要不中断业务的情况下去重复和建立约束的话,有什么好办法呢? 办法: 先不管历史值,新进来的值使用以上方法保证唯一。 然后去重 然后并行添加唯一索引。
代码举例:
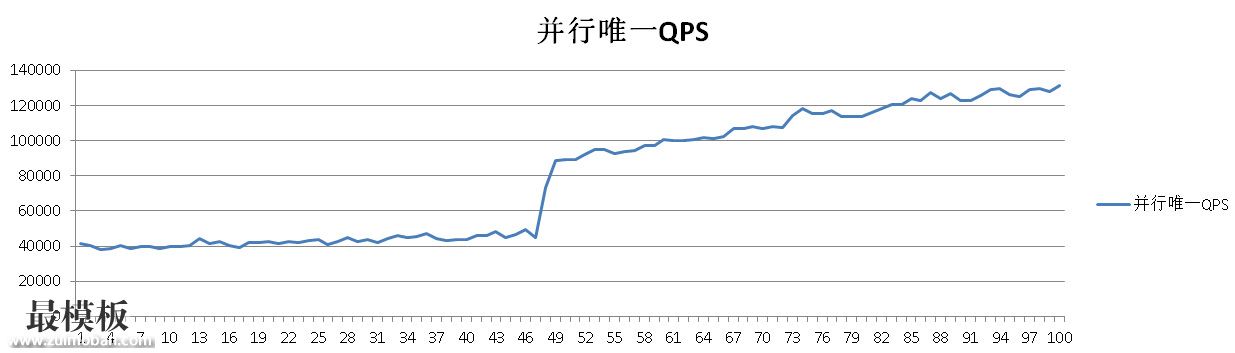
postgres=# drop table tbl; DROP TABLE postgres=# create table tbl(internal_id serial8, nick_name text); CREATE TABLE postgres=# create index idx_tbl_nickname on tbl(nick_name); CREATE INDEX postgres=# drop function load(text); DROP FUNCTION postgres=# create or replace function load(v_c1 text) returns int8 as $$ declare i int8; begin select internal_id into i from tbl where nick_name = v_c1 limit 1; if found then return i; end if; LOOP if ( pg_try_advisory_xact_lock(hashtext(v_c1)) ) then select internal_id into i from tbl where nick_name = v_c1 limit 1; if not found then insert into tbl(nick_name ) values (v_c1) returning internal_id into i ; return i; else return i; end if; end if; end loop; end; $$ language plpgsql strict; 压测500万唯一值。 vi test.sql \setrandom c1 1 5000000 select load(:c1); 52个并发: pgbench -M prepared -n -r -P 1 -f test.sql -c 52 -j 52 -T 100 验证数据唯一性: postgres=# select count(*),count(distinct nick_name) from tbl; count | count ---------+--------- 3966568 | 3966568 (1 row) 性能趋势:
(责任编辑:好模板) |
PostgreSQL 另类advisory lock保证唯一约束法
时间:2016-01-29 18:00来源:未知 作者:好模板 点击:次
在没有唯一约束或者主键约束时,数据库是不保证唯一性的。那么有什么手段来保证呢? 方法 1. 串行操作,先查询,如果没有查到记录,则插入。 这种方法效率非常低: 测试如下:
顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
- 热点内容

-
- PostgreSQL和Greenplum的临时表空间介绍
PostgreSQL的临时表空间,通过参数temp_tablespaces 进行配置,Postgr...
- PostgreSQL基于日志的备份与还原
即预写式日志,是日志的标准实现方式,简单而言就是将对数据...
- PostgreSQL操作符与优化器详解
PostgreSQL 支持自定义操作符,本质上是调用函数来实现的。 语法...
- 更换PostgreSql的data文件夹并重新服务
如果是系统崩溃,需要找回数据,PostgreSQL安装目录的data文件夹...
- PostgreSQL利用pg_upgrade升级版本
PostgreSQL从低版本升级到 新版本,有几种可选的方案。一是使用...
- PostgreSQL和Greenplum的临时表空间介绍
- 随机模板
-
-
 英文球衣外贸网站|ecshop
人气:832
英文球衣外贸网站|ecshop
人气:832
-
 ecshop商品详情自动生成商
人气:3114
ecshop商品详情自动生成商
人气:3114
-
 ecshop新仿中关村模板
人气:588
ecshop新仿中关村模板
人气:588
-
 Varmo英文综合商品商城Ma
人气:134
Varmo英文综合商品商城Ma
人气:134
-
 ecshop仿唯伊网模板|化妆品
人气:1710
ecshop仿唯伊网模板|化妆品
人气:1710
-
 ecshop仿优购网模板|ecshop免
人气:4052
ecshop仿优购网模板|ecshop免
人气:4052
-