利用计算机将大量的文本进行处理,产生简洁、精炼内容的过程就是文本摘要,人们可通过阅读摘要来把握文本主要内容,这不仅大大节省时间,更提高阅读效率。但人工摘要耗时又耗力,已不能满足日益增长的信息需求,因此借助计算机进行文本处理的自动文摘应运而生。近年来,自动摘要、信息检索、信息过滤、机器识别、等研究已成为了人们关注的热点。 自动摘要(Automatic Summarization)的方法主要有两种:Extraction和Abstraction。其中Extraction是抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要;Abstraction是生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。由于自动摘要方法需要复杂的自然语言理解和生成技术支持,应用领域受限。,抽取式摘要成为现阶段主流,它也能在很大程度上满足人们对摘要的需求。 目前抽取式的主要方法:
2007年,美国学者的论文《A Survey on Automatic Text Summarization》(Dipanjan Das, Andre F.T. Martins, 2007)总结了目前的自动摘要算法。其中,很重要的一种就是词频统计。这种方法最早出自1958年的IBM公司科学家 H.P. Luhn的论文《The Automatic Creation of Literature Abstracts》。 Luhn博士认为,文章的信息都包含在句子中,有些句子包含的信息多,有些句子包含的信息少。”自动摘要”就是要找出那些包含信息最多的句子。句子的信息量用”关键词”来衡量。如果包含的关键词越多,就说明这个句子越重要。Luhn提出用”簇”(cluster)表示关键词的聚集。所谓”簇”就是包含多个关键词的句子片段。
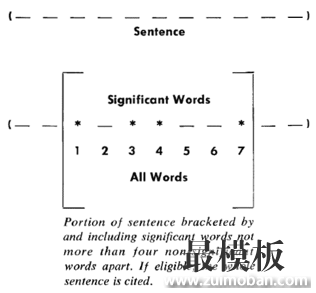
上图就是Luhn原始论文的插图,被框起来的部分就是一个”簇”。只要关键词之间的距离小于”门槛值”,它们就被认为处于同一个簇之中。Luhn建议的门槛值是4或5。也就是说,如果两个关键词之间有5个以上的其他词,就可以把这两个关键词分在两个簇。下一步,对于每个簇,都计算它的重要性分值。
以上图为例,其中的簇一共有7个词,其中4个是关键词。因此,它的重要性分值等于 ( 4 x 4 ) / 7 = 2.3。 然后,找出包含分值最高的簇的句子(比如5句),把它们合在一起,就构成了这篇文章的自动摘要。具体实现可以参见 《Mining the Social Web: Analyzing Data from Facebook, Twitter, LinkedIn, and Other Social Media Sites》(O’Reilly, 2011)一书的第8章,python代码见github。 Luhn的这种算法后来被简化,不再区分”簇”,只考虑句子包含的关键词。下面就是一个例子(采用伪码表示),只考虑关键词首先出现的句子。 类似的算法已经被写成了工具,比如基于Java的Classifier4J库的SimpleSummariser模块、基于C语言的OTS库、以及基于classifier4J的C#实现和python实现。 参考文章:
TextTeaserTextTeaser 原本是为在线长文章(所谓 tl;dr:too long; didn’t read)自动生成摘要的服务,其原本的收费标准是每摘要 1000 篇文章付费 12 美元或每月 250 美元。巴尔宾称 TextTeaser 可以为任何使用罗马字母的文本进行摘要,而且比同类工具如 Cruxbot 和 Summly(在 2013 年 3 月被 雅虎斥资 3000 万美元收购)更准确。其创造者霍洛•巴尔宾(Jolo Balbin)表示,在“发现一些扩展问题,特别是 API 中的问题后”,他决定将 TextTeaser 代码开源。 TextTeaser开源的代码一共有三个class,TextTeaser,Parser,Summarizer。
其中打分模型分为四部分:
开源版本:
自己尝试这个调用Python版本。主要:不要使用pip install textteaser进行安装,该安装方式安装的是这个项目: https://github.com/jgoettsch/py-textteaser,该项目并非算法实现,而是API实现。直接下载代码即可:https://github.com/DataTeaser/textteaser 下载完成后在Windows下运营test.py会报错,报错信息如下:
针对报错信息,做如下修改: 1、将”D:\textteaser\textteaser\parser.py”第62行进行修改:
2、找到”\Lib\site-packages\nltk\data.py”第924行,将
修改为:
注意:TextTeaser目前只支持英文摘要。 TextRankTextRank算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。 TextRank 一般模型可以表示为一个有向有权图 G =(V, E), 由点集合 V和边集合 E 组成, E 是V ×V的子集。图中任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, In(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。点 Vi 的得分定义如下:
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。 基于TextRank的关键词提取 关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
基于TextRank的自动文摘 基于TextRank的自动文摘属于自动摘录,通过选取文本中重要度较高的句子形成文摘,其主要步骤如下:
参考资料:
玻森自动摘要玻森采用的是最大边缘相关模型(Maximal Marginal Relevance)的一个变种。MMR是无监督学习模型,它的提出是为了提高信息检索(Information Retrieval)系统的表现。例如搜索引擎就是目前大家最常用的信息检索系统。大家可能经常会碰到,对于我们输入的一个关键词,搜索引擎通常会给出重复的或者内容太接近的检索的情况。为了避免这个现象,搜索引擎可以通过MMR来增加内容的多样性,给出多方面考虑的检索结果,以此来提高表现。这样的思想是可以被借鉴用来做摘要的,因为它是符合摘要的基本要求的,即权衡相关性和多样性。不难理解,摘要结果与原文的相关性越高,它就接近全文中心意思。而考虑多样性则使得摘要内容更加的全面。非常的直观和简单是该模型的一个优点。 相比于其他无监督学习方法,如TextRank(TR), PageRank(PR)等,MMR是考虑了信息的多样性来避免重复结果。TR,PR是基于图(Graph)的学习方法,每个句子看成点,每两个点之间都有一条带权重(Weighted)的无向边。边的权重隐式定义了不同句子间的游走概率。这些方法把做摘要的问题看成随机游走来找出稳态分布(Stable Distribution)下的高概率(重要)的句子集,但缺点之一便是无法避免选出来的句子相互之间的相似度极高的现象。而MMR方法可以较好地解决句子选择多样性的问题。具体地说,在MMR模型中,同时将相关性和多样性进行衡量。因此,可以方便的调节相关性和多样性的权重来满足偏向“需要相似的内容”或者偏向“需要不同方面的内容”的要求。对于相关性和多样性的具体评估,玻森是通过定义句子之间的语义相似度实现。句子相似度越高,则相关性越高而多样性越低。 自动摘要的核心便是要从原文句子中选一个句子集合,使得该集合在相关性与多样性的评测标准下,得分最高。数学表达式如下:
需要注意的是,D,Q,R,S都为句子集,其中,D表示当前文章,Q表示当前中心意思,R表示当前非摘要,S表示当前摘要。可以看出,在给定句子相似度的情况下,上述MMR的求解为一个标准的最优化问题。但是,上述无监督学习的MMR所得摘要准确性较低,因为全文的结构信息难以被建模,如段落首句应当有更高的权重等。为了提高新闻自动摘要的表现,玻森在模型中加入了全文结构特征,将MMR改为有监督学习方法。从而模型便可以通过训练从“标准摘要”中学习特征以提高准确性。 玻森采用摘要公认的Bi-gram ROUGE F1方法来判断自动生成的摘要和“标准摘要”的接近程度。经过训练,玻森在训练数集上的表现相对于未学习的摘要结果有了明显的提升——训练后的摘要系统F1提高了30%。值得一提的是,在特征训练中,为了改善摘要结果的可读性,玻森加指代关系特征,使得模型表现提高了8%。 (责任编辑:好模板) |
使用Python自动提取内容摘要
时间:2016-09-25 22:14来源:未知 作者:好模板 点击:次
利用计算机将大量的文本进行处理,产生简洁、精炼内容的过程就是文本摘要,人们可通过阅读摘要来把握文本主要内容,这不仅大大节省时间,更提高阅读效率。但人工摘要耗时又耗

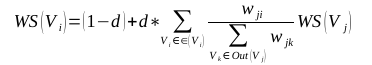
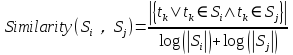 若两个句子之间的相似度大于给定的阈值,就认为这两个句子语义相关并将它们连接起来,即边的权值:
若两个句子之间的相似度大于给定的阈值,就认为这两个句子语义相关并将它们连接起来,即边的权值: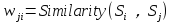
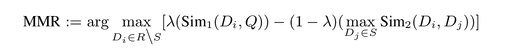
顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
- 热点内容

-
- 不用群发用Python脚本查微信被哪些
Python大法已经被网友们玩儿的出神入化了, 近来有网友用Python写...
- Python实现Linux命令xxd -i功能
一. Linux xxd -i功能 Linux系统xxd命令使用二进制或十六进制格式显...
- Mac上不卸载自带的Python如何使用P
在Mac上用Python脚本测试无疑是最爽的,然而我们组一个:ox:人写的...
- python cmd命令调用
关于python调用cmd命令: 主要介绍两种方式: 1.python的OS模块。...
- 使用Twisted Python和Treq进行 HTTP 压力
从事API相关的工作很有挑战性,在高峰期保持系统的稳定及健壮...
- 不用群发用Python脚本查微信被哪些
- 随机模板
-
-
 ecshop专业汽车用品英文外
人气:1021
ecshop专业汽车用品英文外
人气:1021
-
 免费ecshop便利100带数据微
人气:7852
免费ecshop便利100带数据微
人气:7852
-
 织梦dede机械设备公司企业
人气:3257
织梦dede机械设备公司企业
人气:3257
-
 ecshop鲜花模板
人气:657
ecshop鲜花模板
人气:657
-
 Aspire英文夏季服饰商城m
人气:215
Aspire英文夏季服饰商城m
人气:215
-
 ecshop内衣之仿兰缪模板
人气:576
ecshop内衣之仿兰缪模板
人气:576
-