ECShop指纹识别只是从以下三个入手: 1.meta数据元识别 2.intext:powered by ECShop 3.robots.txt 我们打开一个ECShop网站,看看页面中这几方面的特征。 1.我们现在看看meta标签中有什么特征。下面是我截取的一段HTML。
可以看到,这个网站对meta标签没有处理,保留了ECShop的原始meta。网站是ECShop及其版本是2.7.2。此处也是做版本识别的地方。
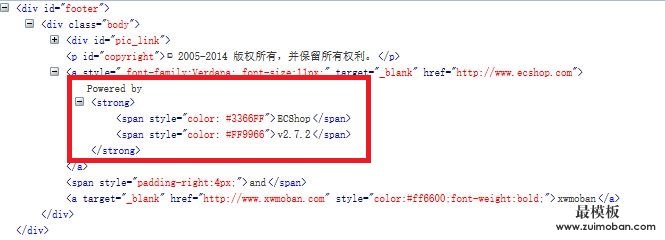
2.再往下查看网页 我们发现在footer中有Powered by ECShop
可以看到,这个网站对ECShop的footer没有修改,保留了ECShop的原始的footer,此处我们可以识别ECShop及其版本。由于一般网站修改此处的较多,这里就不做版本识别了。
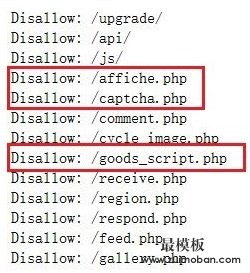
3.对robots.txt内容的检查 robots.txt文件是一个文本文件。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。 当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。 那么这可以被我们利用,以识别ECShop,看下面截图,我们发现有些文件是ECShop特有的,比如:/affiche.php、/good_script.php、/feed.php。那么,如果存在这几个特征,我们可以基本确定这就是一个ECShop CMS了。
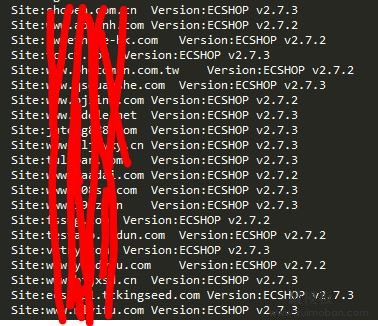
将ECShop指纹单独保存为识别字典 ecshop_feature.py
下面是程序得到的部分结果
|
如何作ECShop指纹识别版本判断代码
时间:2014-12-19 14:41来源:未知 作者:好模板 点击:次
ECShop指纹识别只是从以下三个入手: 1.meta数据元识别 2.intext:powered by ECShop 3.robots.txt 我们打开一个ECShop网站,看看页面中这几方面的特征。 1.我们现在看看meta标签中有什么特征。下面

顶一下
(0)
0%
踩一下
(3)
100%
------分隔线----------------------------
- 上一篇:ecshop后台订单自动确认开发详解
- 下一篇:ecshop调试php语句书写规范
- 热点内容

-
- ecshop调用后台指定广告位下所有广
我们在ecshop模板制作当中,有时候对广告的调用不能局限于默认...
- 如何修改ecshop实现每个页面显示友
如何修改ecshop实现每个页面显示友情链接,具体分 为两步: 1、打...
- ecshop调用指定栏目下的商品的方法
ecshop调用指定栏目下的商品,第一步 在ecshop系统目录文件找到i...
- Shopex到ECShop的转换教程
Shopex到ECShop的转换教程...
- ecshop时间问题请注意/data/config.php
ecshop 处理时间,绕来绕去, 后台的时区设置, 并非以服务器为...
- ecshop调用后台指定广告位下所有广
- 随机模板
-
-
 ecshop免费模板之Superfly整站
人气:5360
ecshop免费模板之Superfly整站
人气:5360
-
 ecshop礼品网模板
人气:1750
ecshop礼品网模板
人气:1750
-
 免费ecshop仿小米手机商城
人气:8204
免费ecshop仿小米手机商城
人气:8204
-
 韩国夏日风格ECSHOP服装模
人气:1067
韩国夏日风格ECSHOP服装模
人气:1067
-
 高仿|精致lightinthebox模板
人气:5153
高仿|精致lightinthebox模板
人气:5153
-
 ecshop易趣英文外贸模板
人气:1288
ecshop易趣英文外贸模板
人气:1288
-