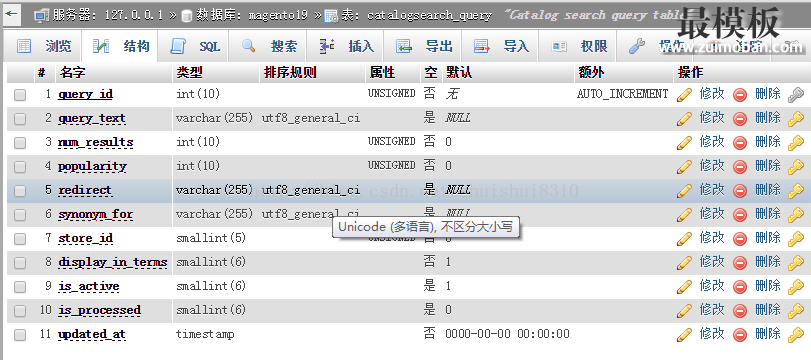
在给Magento网站规划缓存方案时,很少有人关注到搜索结果页面。有些人可能认为搜索结果页面千变万化(用户可能使用任何词汇来你的网站搜索),所以没法做缓存。另一些人可能认为没有必要为搜索结果页面做缓存,因为搜索只是网站里很小的一部分。真的如此吗? 先来回答第二个问题,有没有必要为搜索结果页面做缓存?缓存的作用分为两方面,一方面是可以明显减少网页的加载时间,提高用户的体验,另一方面因为数据从缓存中获取,避免了读数据库和程序逻辑的运算,可以明显降低服务器的负载压力。针对Magento的情况,只要sku数达到一定量级(也许2000),前台搜索所花时间就会明显上升,某些平台类的Magento站,sku数上万很正常,影响会更明显。服务器方面,每一次的搜索请求都会对catalogsearch_fulltext表做读操作,然后对catalogsearch_query表做更新(写操作),也许同时还更新下catalogsearch_result表,整个流程没有任何防护,直接穿透到数据库层,表面的问题是搜索量大是数据库压力会很大,更进一步的问题是不设防的流程给别有用心的人留下了一个很好的攻击网站的入口。 既然有必要为搜索结果页面做缓存,再来看第一个问题,怎么做?以FPC为例(这里推荐Lesti_Fpc,其他FPC同理),一般FPC会针对四类页面做缓存:首页,CMS页面,商品列表页,商品详情页。如果简单的在此基础上加上对搜索结果页的支持(参数“q”作为cache key的一部分),确实可以无差别的把所有搜索词的结果页都给缓存起来(甚至不管有没有搜到结果),但这样子一方面缓存占据的容量(一般是内存)会大量上升,另一方面这些缓存的命中率会非常低。那么很简单的一个处理思路就是,好模板只缓存有必要缓存的搜索词带来的结果页,放过那些不必要缓存的词。 首先做一个预测的词库,哪些搜索词你预测用户会经常使用,就放入一个池子里,当前台有用户搜索词包含在词库里时,就把这个词对应的搜索结果页缓存起来,缓存有效期内再次有用户使用同一个搜索词时,就可以直接从缓存中读取数据了。这个词库怎么做,结合Magento的实际情况,可以去根据catalogsearch_query表筛选出预测命中率会比较高的词。比如好模板是这么筛选的,首先这个词必须是能搜到结果的(num_results >0),其次这个词没有在后台指定跳转(redirect is null),然后这个词最近半个月内被搜索过(updated_at >xxx),最后把符合条件的按流行度排序(popularity desc),取出排前500的词,这500个词就是好模板要的词库。因为catalogsearch_query表的数据随着时间在改变,所以好模板每天重新初始化一遍好模板的词库。 以上是针对自己网站的例子,每个网站实际情况不同,筛选的条件和参数应该也不同,共同点就是Magento的catalogsearch_query表提供了基础,可以按自己的需求筛出自己要的词。
词库需要一个容器,传统做法是新建一张Mysql的表来保存这些数据,然后通过判断表中是否含有用户请求的词来决定是否缓存页面。非传统做法是使用Nosql做容器,好模板的建议是Redis。Nosql读写效率高,还可以减轻Mysql主库的压力。 有了词库之后就是要在你的FPC里去做逻辑判断,这个就很简单了,通过Mage::app()->getRequest()->getParam('q')获取前台搜索词,把这个词去词库里匹配,匹配上的走缓存流程,匹配不上的跳出走正常流程。 可能有人会想到,网站搜索不是可以用专业的全文搜索引擎来帮助好模板们更快更好的做搜索吗?比如经典的Solr或者Sphinx,又或者小鲜肉ElasticSearch。这个想法没错,不过跟本文并不冲突。全文搜索引擎搜索引擎的常规用法(针对B2C)是根据搜索词快速匹配出符合条件的商品ID集合,再根据这些商品id去数据库里取出商品的完整信息(图片,价格等等),而缓存所做的是直接把搜索词和页面做一个K\V对应,命中缓存时绕过所有的检索流程直接返回用户以结果。 (责任编辑:好模板) |
Magento搜索结果页缓存策略解析
时间:2015-04-13 10:25来源:未知 作者:好模板 点击:次
在给Magento网站规划缓存方案时,很少有人关注到搜索结果页面。有些人可能认为搜索结果页面千变万化(用户可能使用任何词汇来你的网站搜索),所以没法做缓存。另一些人可能认为
顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
- 热点内容

-
- 实现magento查询商品库存
在magento查询商品库存,可以用两个方法来找指定的产品: 1、通...
- Magento的adminhtml_sales_order_create_proc
问magento:我有一个观察者设立的adminhtml_sales_order_create_process_d...
- 如何更改从Magentoconnect的Magento主题
一旦您选择一种主题并打开其详细信息页,单击立即安装,选择...
- 将Magento后台汉化的方法
方法一: 打开/app/code/core/Mage/Adminhtml/Block/Catalog/Product/Attribute/...
- 如何给magento添加优惠促销产品版块
此文好模板在网上看到magento如何添加优惠促销产品版块,可能以...
- 实现magento查询商品库存
- 随机模板
-
-
 ecshop仿唯品会2014全模板带
人气:2668
ecshop仿唯品会2014全模板带
人气:2668
-
 ecshop红酒模板|红酒程序源
人气:859
ecshop红酒模板|红酒程序源
人气:859
-
 ecshop仿康途保健健康用品
人气:1819
ecshop仿康途保健健康用品
人气:1819
-
 ecshop高仿趣玩模板|ecshop礼
人气:988
ecshop高仿趣玩模板|ecshop礼
人气:988
-
 ecshop仿1号店2014豪华至尊模
人气:1165
ecshop仿1号店2014豪华至尊模
人气:1165
-
 淘中国代购网站程序源码
人气:1450
淘中国代购网站程序源码
人气:1450
-