梳理下使用移动端数据库的一些重要知识点,再综合对比下sqlite和CoreData的优缺点,希望能帮助一些这方面经历较少的同学少走一些弯路。 为什么要用数据库iOS端持久化的方案选择比较多,NSUserDefault,Keychain,File,sqlite都可以帮助存储关键的业务数据。NSUserDefault和Keychain都是轻量级解决方案,自定义数据格式的File则读取麻烦一些,每次更新部分数据都会导致整个文件io,数据的结构一旦复杂起来,最后还是会走向sqlite。 sqlite是移动端的轻量级数据库解决方案,它的应用之广几乎已经遍及我们日常生活当中所使用的主流App,大部分人所熟知的CoreData或者FMDB,其内核都是基于sqlite。现在第三方的封装使得sqlite的使用更为便捷,但数据库是计算机科学一大知识体系,其涵盖的知识点相当庞大,简单用起来很简单,用得合理用得溜就不那么容易了。一个高频次使用的App,一年之后还要保持高效的读写真不是个简单的活。 在具体深入CoreData和Sqlite细节之前,先梳理下数据相关的重要知识点,以下关于数据库的讨论都是以sqlite为范畴。 Relation(关系) vs Object(对象)在开始讨论之前,分清楚Relation(关系)和Object(对象)之间的差别非常重要。这两个概念对很多最初接触数据库的同学来说可能有些模糊不清,特别是直接上手一些第三方封装过Sqlite库,很容易认为表和对象之间存在天然的映射关系,毕竟table当中的记录刚好可以对应一个object。 其实对于sqlite这类关系型数据库,在数据的存储和表现形式上和面向对象当中的object还是存在很大差异的。我们平常使用OOP编程语言的时候,习惯性思维会用对象去模拟,描述一切和业务相关的存在,比如用户,商品,购物车,浏览记录,购买记录等等,这些可以方便的对应到一个个的table,但Object在描述对象的时候更加灵活,比如UserProfile对象,他可以有一个property来描述他的朋友列表: @interface UesrProfile : NSObject @property (nonatomic, strong) NSArray* friends; @end 可以用Array这类集合的概念进一步细化表示Object,但sqlite的table只能存储scalar type,也就是单一数据类型,无法去存储Array,关系型数据库的做法通常是通过主键和外键,在两个表之间来表示关系。当然我们也可以在UserProfile表中增加一个自定义的blobdata或者格式化后的特殊String来存储array,但这种设计已经脱离关系系数据库的范畴了。 总而言之,sqlite这类关系型数据库更加强调关系,将内存中的OOP对象保持至数据库的时候需要进行一步转化的工作,将OOP的Relation转化成sqlite的Relation。 index(索引)索引是平常数据库使用当中基础中的基础,如果只是将数据转化为表进行保持,下次用时再取,在表记录变得庞大以后很容易出现性能问题。用数据库保持数据的另一大好处是数据的读取可以很快,和传统的文件存储相比,性能不在一个量级。当然我们需要索引的帮助,index可以让我们以特定的方式快速读取或查找某些记录,有多快呢?理解index有多快需要一些算法知识的储备,并不是很复杂的算法。 我在之前一篇文章中介绍过 集合类查找数据的一些算法基础 ,抽象来看,数据库也可以看做是一种集合类。 对于无序Array,我们需要完整的遍历整个集合才能找到我们感兴趣的元素,查找的时间复杂度为O(N)。 有序的Array,二分法查找可以将时间复杂度降为O(logN),但插入为O(N)。 有没有一种数据存储方式可以同时让insert和search都快呢?Tree可以,Binary Search Tree可以在insert和search之间取得平衡,达到O(logN)的速度。 再继续深入之前,我们先抽象的看下sqlite是如何存储数据的。
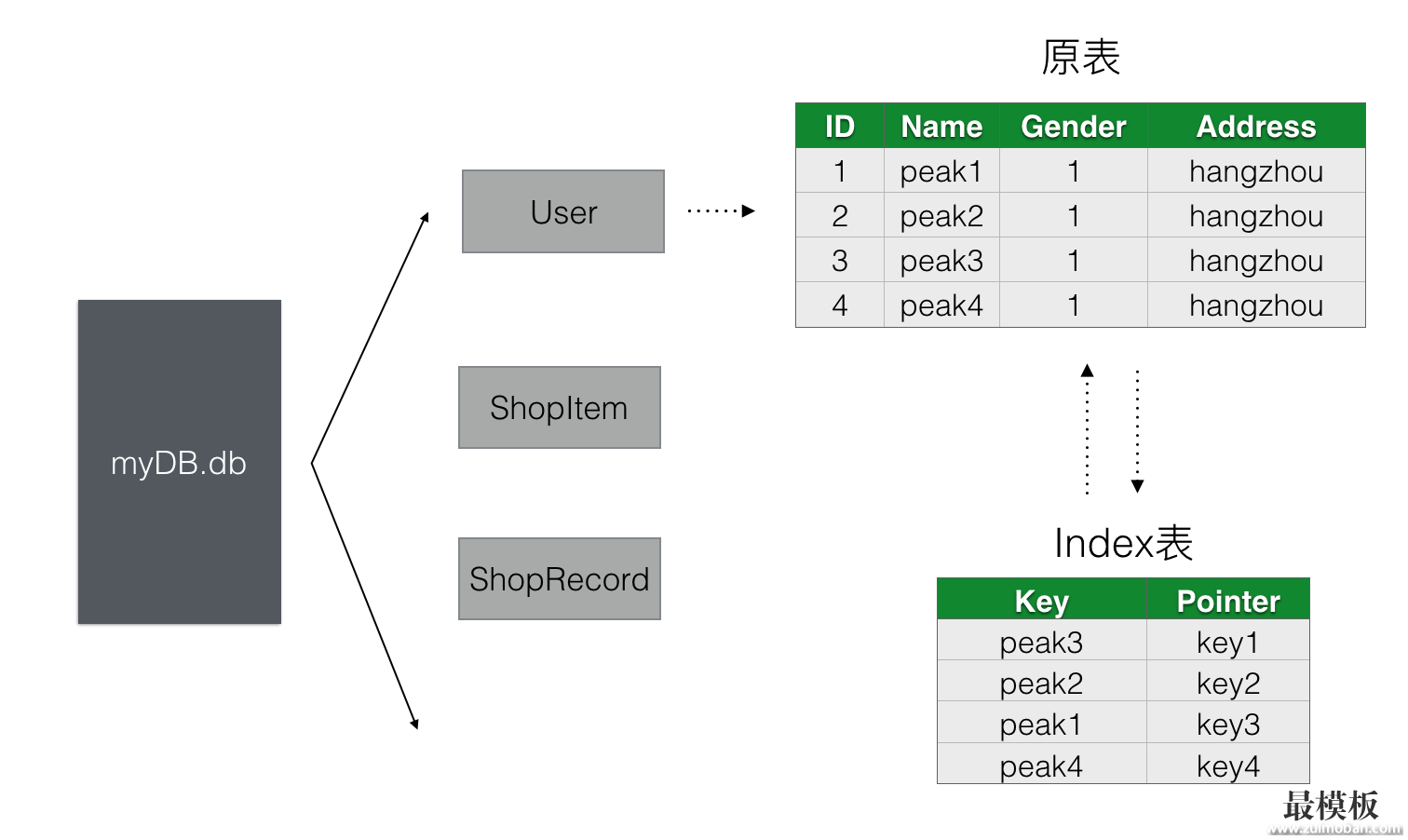
所谓的建索引是给原数据表新建了一个index表来方便查找,如果我们给User表中的Name做了索引,当我们根据Name去做sql查询的时候,第一步其实是去User表对应的Index表去做查询,Index表以Name为key建立了一个B+Tree的树形结构。上图中虽然Index表看上去也是一个table,但背后其实是以B+Tree为数据结构进行了整理,在B+Tree(Index表)中找到记录A之后,第二步可以从A记录中的地址信息找到原User表对应的记录信息。这里可以看出主要的性能损耗在第一步,第二步是普通的磁盘I/O。索引并不是万金油,我们可以通过分析第一步来了解建立了索引之后的查询性能瓶颈在哪。要分析第一步,还得先了解其他几个知识点: 磁盘I/O瓶颈在学校学习计算机基础这门课程的时候,我们都知道内存(Memory)较之于磁盘(Disk),读取速度快,但由于价格贵所以空间比Disk小。也正是由于这个原因导致我们大尺寸的数据都只能存在Disk上,用的时候再去内存取,没读一次就触发一次磁盘I/O,同理我们的sqlite其实说白了就是一个xxx.db文件,每次去做sql查询的时候就要去读文件,大多数时候一次查询往往无法通过一次I/O完成,所以如何减少磁盘I/O的次数成为我们优化sqlite性能的关键指标。 理解磁盘和内存寻址性能的差异还有一个很重要的知识点,Random Access和Sequential Access。Random Access是指我们访问的地址是随机分布的,当前需要读取0x00000001,下一刻可能读取0x000A0001。而Sequential Access则是严格按照顺序寻址的,0x00000001下一刻跟的是0x00000002。对于内存来说,Random Access和Sequential Access在性能上没有任何差异。对于Disk,Sequential Access也能很好的适应,磁盘的机械旋转就能顺利的读到连续的地址,Random Access就比较费时了,可能需要磁头和磁盘的多次机械运动才能重新定位到目标地址。 磁盘读取方式从以前计算机基础教程当中我们都见过机械磁盘物理寻址的示意图,一个磁头牵头移动配合磁盘的旋转来找到具体的分区和地址,正是由于磁头的寻道和磁盘的旋转都是机械运动,直接导致寻址性能和内存寻址差了几个量级。磁盘读取数据的时候都是以Page为单位,页(page)的概念很重要,Page是计算机存储时所使用的基础逻辑单位,内存和磁盘当中的数据存储和交互都是以页为单位。即使内存只需要1个字节的数据,从磁盘读取的时候也是拿到一个或多个page,这是一种常用的预先缓存策略,因为内存在程序执行的下一刻极有可能会需要读取这一个字节周围的数据,明白页的概念有助于我们形成数据库读取数据时的抽象示意图,对于后面我们分析一些sqlite的性能问题有很大的帮助。 说到Page,还值得啰嗦一些。Page这个计算机基础概念在很多场景中都有用到,很容易混淆。
这些都统称为Page,但在不同场景含义并不相同,阅读英文文档的时候需要仔细区分。 table记录的存储方式明白了Page的概念后,还需要了解一个table当中的记录是如何以页为单位存储的。做一个简单的计算就能够明白其中的关联。上图中User表各字段我们分别假设type为:ID(Int,4 Bytes),,Name(String,128 Bytes),Gender(Int,4 Bytes),Address(String,128 Bytes),所以一行记录所占的空间就是4+128+4+128=264 Bytes。假设一个Page大小为4 KB,那么一页我们可以存储4*1024/264≈15条记录,也就是说我们一次I/O我们可以获取到User表15调记录,如果这15条记录中不包含我们的查找目标,我们需要再做一次I/O。不过我们建立的索引表并不需要包含原表的全部数据,比如上图中Index表只需要Name(128字节)和Position(4字节)即可,那么一页可以存储 B+Tree上面提到使用Tree来存储数据可以获得不错的Insert和Search效率,使用Binary Search Tree或者红黑树可以让查找的时间复杂度为O(logN),logN表示树的高度h,即使是完全平衡的红黑树,树的高度都无法控制在理想的范围,而B Tree和B+Tree相比能够将h控制一个极小的值,不过节点数是一定的,高度h变小了,每个节点的子节点数(degree)必然就增加了,由于查找的性能和树的高度相关,所以B+ Tree是更好的选择。关于B+ Tree的算法原理这里就不展开了,感兴趣的同学可以自己搜索相关资料。 根据上面几个知识点,我们可以在脑中形成一个抽象的查询流程:
接下来我们根据上述信息做简单的推理,得出一些和index相关的Best Practice。 场景一:索引并不是越多越好。虽然索引能加快查询的速度,但同时增加了额外的一个表来存储B+Tree结构的数据,1million条记录就对应一个1million条记录的Index表,额外开销非常可观。所以我们平常应该只给必要的字段(有被查询需求)建索引,而且索引还会增加insert和delete的时间复杂度。 场景二:给数值类型建索引会比String类型建索引,效率更好。其实更合理的表述应该是,建立Index的字段的Data Type大小越小,我们索引查询的性能就越高。原因很简单,数据越小,单条记录的磁盘开销就越小,一个Page所包含的记录数量也就越多,这样我们磁盘I/O的时候自然命中率就越高。这也是为什么我们总是给ID建索引,而很少对Name建索引。当然这种性能的差异只有在表记录非常庞大的时候才能看出差别。 场景三:索引之后查询并不一定快可能有些人觉得建了索引查询就没性能问题了,比如上面User表,针对ID建了Index。下次查询的时候就可以随心所欲写sql了,实际上还是需要具体场景具体分析。 索引使用B+Tree作为背后的数据结构支撑,其本质上还是一种有序的数据结构,对于B+Tree来说,第1000个节点需要连续读取1000个节点才能获取到。所以当我们执行如下sql的时候,速度并不理想: select Name from User order by ID limit 1000, 10 即使我们对ID做了索引,读取1001~1010个元素和读取第1~10个元素速度完全不同,这里的关键在于offset,limit这种写法对于sqlite来说效率很低,每次查询的时候第一步要跳到offset,需要执行O(offset)次读取才能定位到目标位置。正确的做法是使用>=或者<=来做第一次跳转: select Name from User where ID >= 1000 order by ID limit 10 这样第一步可以使用Binary Search快速定位到大于1000的位置,再连续的读取10个节点就可以了。 Sqlite有篇文档 解释了这种场景,在设计翻页的时候我们经常会遇到。 索引优化是个复杂的问题,需要大量的理论和实践来认知,但上述这些基础知识点的理解可以帮助解决大部分应用场景下遇到的索引问题,或者是作为分析复杂场景的起点。 Sqlite基础知识移动端的数据方案大多是基于sqlite,CoreData,FMDB等都不例外,掌握一些sqlite的基础知识对于平常选择技术方案,分析技术问题很有帮助。 文件分析我们先来直观的认识下sqlite,sqlite的主要存储其实就是一个文件,另外再配有两个功能辅助文件。使用itools将 App的db文件导出可以看到三个以下文件:
其中MyDB.db不用多说,是各个tables存储的位置,前面提到的原始表,索引表等都在这个文件当中。 MyDB.db-wal和MyDB.db-shm是做什么用的呢?-wal是sqlite的日志文件,全称是write-ahead log。在wal出现之前,sqlite使用的是-journal文件,现在有些sqlite的版本还是使用的-journal模式。简单来说,-journal是用来配合事务(Transaction)做原子提交的,每次提交一个事务之前,sqlite会先将.db的状态保持至-journal文件,然后再提交事务数据,如果事务顺利提交,再删除-journal文件中的状态,如果事务中途被异常中断,比如断电或者程序crash,下次sqlite被打开的时候,会去检查-journal文件,如果发现日志,会将.db文件恢复到事务之前的状态,所以-journal文件是sqlite的rollback日志。 -wal文件是-journal的替代品,其工作方式和journal刚好相反,所有的事务都是先提交到wal文件,原db文件保持不变,到特定的时机点时才把wal文件merge到db文件。所以如果是使用journal模式,新提交的数据是在db文件中,而使用wal模式的话,新提交的数据要在wal文件中查找。wal的好处是,允许不同的连接,一个读db文件,另一个写wal文件,读和写操作可以并行。 wal文件和db文件一样是以page为单位存储的,默认情况下,如果wal文件达到1000个page(一个page为1KB大小)的时候,会产生一次checkpoint行为,即把wal文件中的数据append到db文件之中。CoreData据我测试wal文件产生checkpoint的临界值是4000page,也就是4M大小。所以大家平常使用CoreData提交数据的时候,可以清楚的看到wal文件慢慢变大,而db文件保持不变,直到wal文件接近4M大小的时候,才merge到db文件之中。 当然也可以通过命令行的方式手动merge wal和db文件,后面实践的时候再做演示。 MyDB.db-shm文件是用来辅助-wal文件的,shm是shared memory的缩写,可以看做是wal文件的一个index文件,是为了辅助sqlite快速定位wal文件信息(每一次完整的commit)。shm文件之中本身不存储任何和table相关的数据,如果我们用vim将-shm文件打开是看不到任何业务数据记录的。 到这里我就对sqlite的三个相关文件有了初步直观的认识,下面我看下如何用命令行去读取db当中的数据。 使用命令行分析sqlite db文件sqlite的命令行交互方式很丰富,下面我做下最常用的使用方式演示: 打开db sqlite3 MyDB.db 展示db文件中的tables .tables 展示某个table的字段构成(schema) .schema tableName 执行sql语句 select * from tableName where ...; 展示结果的时候显示顶部column名称 .head on 通过上面简单几步就可以通过终端直观的浏览一个db当中的table数据。更多的命令可以查看 这篇文档 。 对于命令行交互还一个PRAGMA语句值得一提,PRAGMA语句提供了更丰富全面的交互支持,比如上面我们所提的手动checkpoint操作,可以在打开db的前提下,通过如下PRAGMA语句来完成: PRAGMA checkpoint_fullfsync = true 在退出sqlite命令模式的时候,就可以发现wal文件被清空了,数据全被append到db文件之中。 平常debug的时候,经常需要查看数据是否写成功了,使用命令行交互查看数据快速高效。 CoreDataCoreData具体怎么定义可谓是众说纷纭,关于它的吐槽和总结非常之多。在我看来,CoreData是作为database的存储和oop的Object之间的桥梁,并在存储之上提供了一层object graph的封装,这个object graph才是CoreData的重点,CoreData并不能算是ORM,它的存储后端虽然是关系型数据库sqlite,但也可以是其他类型的数据库,重点在于object graph,为了方便开发者快速构建model层,所有关于CoreData的功和罪都是源自于这一善意的出发点。 从xcdatamodeld文件的图形编辑界面,到NSFetchedResultsController,可以看出苹果是想提供一整套完整的方案,从底层database的数据存取,到应用层Controller的数据的展示和更新,一站式解决。对于简单小型应用,使用起来确实很简便,能快速的搭建一套持久化方案。但是用简单的方案来简化原本复杂的流程,就不可避免的要隐藏和屏蔽一些原本需要被暴露的细节,丧失可定制化的灵活性。这也是为什么CoreData在被应用于复杂项目时会不停踩坑的根本原因。 我个人认为,对于业务相对复杂的项目,持久化以及model的处理应该被隔离在单独的一层,不应该将持久化的处理直接延伸至应用层(Controller)。通过interface分层,可以将model的变化和业务流程独立开来,维护单独的model layer可以更方便我们查看和控制整个程序的状态变化,在必要的时候甚至可以做持久层的数据迁移。 在ORM的处理方案中,Active Record鼓励将table中的数据直接对应到model,同时在model之中编写domain logic,我认为domain logic不应该包括具体的应用层业务流程,而是指和model本身相关的逻辑,比如提供fullName方法拼接firstName和lastName。而在Controller层使用model的时候需要做多一步model的转换,做持久层的model和应用层的model之间的隔离。 CoreData正是因为想做的太多,导致最后既不是database,又不像ORM,其提供的一套不透明的object graph机制使得做性能分析优化的时候踩坑不断。我们具体来看下CoreData和sqlite有哪些差别。 CoreData和Sqlite最大的区别在于,CoreData更接OOP的Object,而FMDB这种Sqlite的封装则更靠近关系型存储。CoreData虽然是基于sqlite的封装,但为了贴近OOP的思维方式,牺牲或者说屏蔽了很多数据库本身的特性。 不透明的object graphobject graph并不是新的概念,无非是把db当中的table映射成了上层的model,有些model相互之间产生关联,彼此引用,形成一张完整的graph。object graph不但做了orm的工作,还暗自维护了model的cache,还将磁盘的io操作也替你屏蔽了,所以在使用model的时候,你并不知道什么时候会触发具体的I/O,很有可能是在你访问如下属性的时候: NSString* name = userEntity.name; 这一切都会自动发生,有CoreData替你完成,方便的同时,也失去了深度控制model行为的可能。 批量更新在iOS 8之前,由于CoreData提供的都是一个个的model,所有要做批量更新的话,只能一个个遍历然后调用commit,无法批量提交更新导致一些场景有性能问题。iOS 8之后CoreData终于提供了批量更新的接口:
NSBatchUpdateRequest *req = [[NSBatchUpdateRequest alloc] initWithEntityName:@"Message"];
req.predicate = [NSPredicate predicateWithFormat:@"read == %@", @(NO)];
req.propertiesToUpdate = @{
@"read" : @(YES)
};
req.resultType = NSUpdatedObjectsCountResultType;
NSBatchUpdateResult *res = (NSBatchUpdateResult *)[context executeRequest:req error:nil];
可上面看上去还是更像sql语句一些,由此可见苹果还是一直在尝试让CoreData变得更完美和更全能,既能像sql一样思考,又提供model层的便捷。 没有Primary Key如果使用过CoreData就会发现其UI操作界面并没有设置Primary Key的地方,如果你想让你的Key是唯一的,只能自己在内存中去计算维护一套生成key的机制,CoreData通过Object的这一层抽象将Primary Key屏蔽掉了。一种简答的唯一性Key生成机制是:利用NSUserDefault存储一个int,每次read都+1,然后存回NSUserDefault,read和write都是加锁,性能上虽然差一些,完全可以满足移动端的需要。 数据库多线程模型全面的理解sqlite的多线程模型对于编写复杂数据存储场景的app很有必要,先来看些sqlite多线程相关的基础知识。 sqlite在多线程访问的场景下,通过db锁来控制并发,db锁有五种状态。
从上面的几种锁状态可以得出结论,sqlite支持多个读操作并发执行,但同时只能有一个写操作在发生。从Reserved开始一直到Exclusive,都只能有一个写操作在进行,但在Pending之前,新的读操作都是可以继续加入,这种粒度的锁对多线程读写并发场景下读操作有较好的支持,同时也通过Pending锁避免了write starvation的问题。 针对上述锁的分析,我们在建立多线程模型的时候,主要有以下几种模型:
第一种是最简陋的做法,写操作会影响UI线程的性能。第二种是比较普遍的做法,写操作都放到子线程当中,当然子线程也可以产生读操作,这种做法可以做到读写并发,同时又不影响UI线程。第三种做法使用多个写线程来提高写操作的效率,但从上面锁状态可以看出,从Reserved开始就已经是写操作互斥了,我个人感觉这种做法对写操作性能的提升相当有限。一般推荐第二种做法。 CoreData的多线程模型CoreData默认使用的是sqlite的多线程模式,这种模式下不能跨线程共享数据库的连接,虽然不清楚CoreData的内部实现细节,总体使用下来感觉一个NSManagedObjectContext对应一个数据库连接,同时再维护一套自己的object graph,object graph并不是多线程安全的,object graph当中的object 不能跨线程直接共享,NSManagedObjectContext也不能跨线程使用。所以使用CoreData建立多线程模型的时候有如下规则:
不同的context之间并不是自动同步数据的,在write context写入的数据并不能直接在main context中读取到。我们需要自己建立同步机制,一般有两种方式。 方式一:监听context的写通知
//主线程监听write context的写操作
[[NSNotificationCenter defaultCenter] addObserver:self.observer
selector:@selector(mocDidSave:)
name:NSManagedObjectContextDidSaveNotification
object:self];
//merge 来自 write context中的数据变化
NSError *error = nil;
[[self managedObjectContextForMainThreadWithError:&error] mergeChangesFromContextDidSaveNotification:saveNotification];
方式二:共享context为了避免多个context之间的merge操作,可以在多个context之间建立paret child关系,使用这种方式一般会建立一个公共的background context,其他所有的main context和background context都是它的child。这种方式确实可以避免merge的问题,但我感觉本质上是把所有的读和写操作都串行化了,虽然最后读写行为都是在子线程发生,但并发的性能反而不如方式一好。 CoreData的第三方封装也有一些,我使用过其中一款 RHManagedObject ,在多线程上根据上述第一种方式做过一些修改,目前经过2年多的实际项目验证还比较稳定,感兴趣的同学可以在我公众号回复db,获得demo的下载地址。 结束语我个人就CoreData和FMDB都在实际项目当中使用过,总体感觉CoreData更适合小型存储需求的项目,快速搭建方便上手,Sqlite或者FMDB则更适合复杂存储需求的项目,更灵活更可控。尤其是对读写操作频繁的App比如IM这一类,需要对读写并发做深入优化时,CoreData并不是一个好的选择。 (责任编辑:好模板) |
iOS端数据库解决方案分析
时间:2016-11-07 22:28来源:未知 作者:好模板 点击:次
梳理下使用移动端数据库的一些重要知识点,再综合对比下sqlite和CoreData的优缺点,希望能帮助一些这方面经历较少的同学少走一些弯路。 为什么要用数据库 iOS端持久化的方案选择比较

顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
- 上一篇:iOS深拷贝和浅拷贝的详解
- 下一篇:iOS在项目中使用RSA算法
- 热点内容

-
- iOS几句话实现导航栏透明渐变
首先我们来看下效果 Gif1.gif 一开始当我们什么只设置了一张图片...
- iOS开发WebView进度条
类似Safari的加载进度条,除了比HUD更加简洁,也有更好的用户体...
- 清理ios项目不用的图片资源
项目经过需求的变更,产品本身的迭代,会经过多次的改版,有...
- iOS通讯录的简单实现
本文是基于UITableView实现一个简单的通讯录,支持滑动删除与标...
- IOS之Runtime
Runtime是什么?我相信大家都很熟悉吧,下面让我们来直接进入正题...
- iOS几句话实现导航栏透明渐变
- 随机模板
-
-
 shopex红色综合批发商城
人气:642
shopex红色综合批发商城
人气:642
-
 Ecmall仿亚马逊英文外贸多
人气:1755
Ecmall仿亚马逊英文外贸多
人气:1755
-
 绿色保健品仿薄荷ecshop模
人气:787
绿色保健品仿薄荷ecshop模
人气:787
-
 Welldone外贸综合时尚设计
人气:203
Welldone外贸综合时尚设计
人气:203
-
 零食食品网站程序源码|
人气:4038
零食食品网站程序源码|
人气:4038
-
 英文内衣外贸商城|ecshop英
人气:448
英文内衣外贸商城|ecshop英
人气:448
-