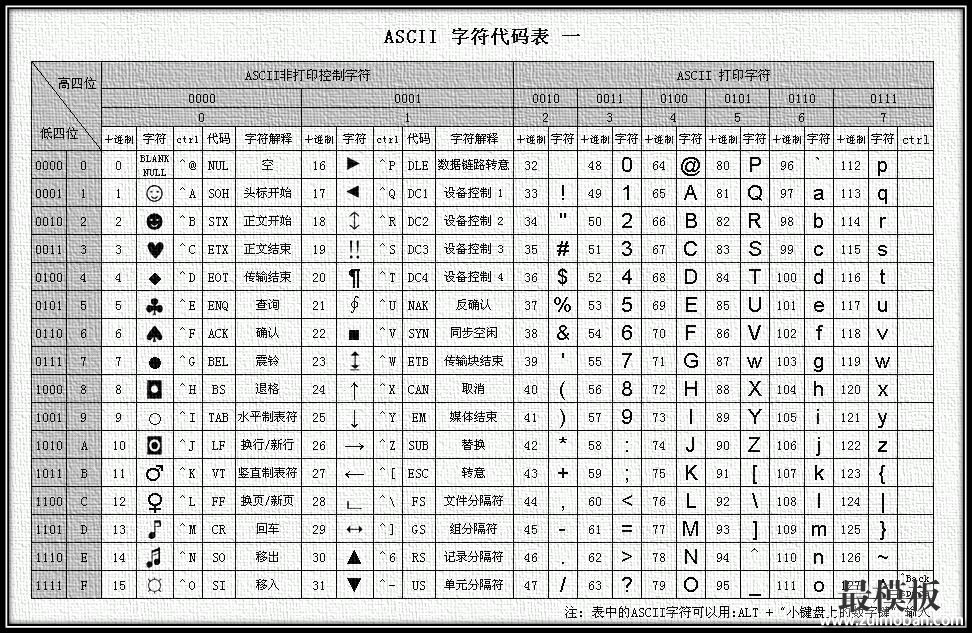
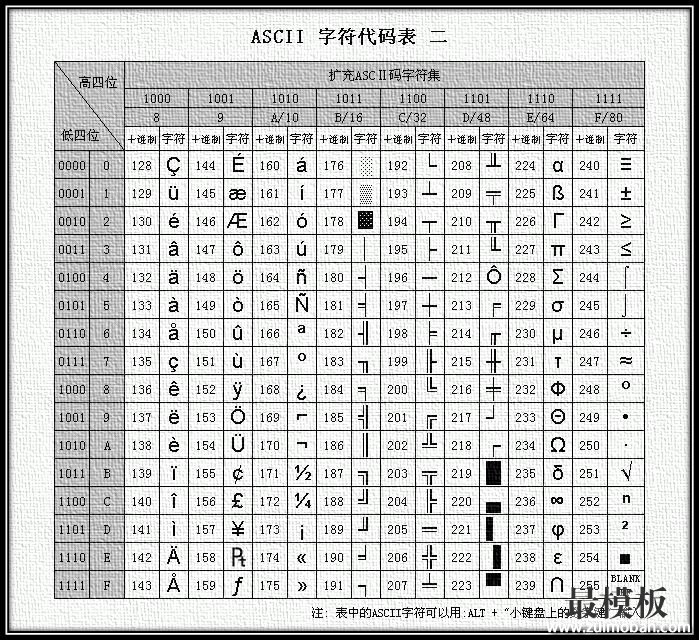
由于项目的需要,一个系统中的字符环境需要改为中文环境,以前没有对此做太多留意,现对操作做如下记录,有需要的朋友也可以大致了解一下 一、基础知识:计算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。通俗的说,按照何种规则将字符存储在计算机中,如'a'用什么表示,称为"编码";反之,将存储在计算机中的二进制数解析显示出来,称为"解码",如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,则导致'a'解析成'b'或者乱码。 字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。 字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。 二、常用字符集与字符编码 常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。它是现今最通用的单字节编码系统(但是有被Unicode追上的迹象),并等同于国际标准ISO/IEC 646。 ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。 ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。ASCII字符集映射到数字编码规则如下图所示:
ASCII的最大缺点是只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语(而且在处理英语当中的外来词如nave、café、élite等等时,所有重音符号都不得不去掉,即使这样做会违反拼写规则)。而EASCII虽然解决了部份西欧语言的显示问题,但对更多其他语言依然无能为力。因此现在的苹果电脑已经抛弃ASCII而转用Unicode。
GBXXXX字符集&编码
计算机发明之处及后面很长一段时间,只用应用于美国及西方一些发达国家,ASCII能够很好满足用户的需求。但是当天朝也有了计算机之后,为了显示中文,必须设计一套编码规则用于将汉字转换为计算机可以接受的数字系统的数。 天朝专家把那些127号之后的奇异符号们(即EASCII)取消掉,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。 上述编码规则就是GB2312。GB2312或GB2312-80是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集・基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。下图是GB2312编码的开始部分(由于其非常庞大,只列举开始部分,具体可查看GB2312简体中文编码表):
(责任编辑:好模板) |
centos6修改字符环境为中文环境
时间:2016-09-28 11:46来源:未知 作者:好模板编辑 点击:次
由于项目的需要,一个系统中的字符环境需要改为中文环境,以前没有对此做太多留意,现对操作做如下记录,有需要的朋友也可以大致了解一下 一、基础知识:计算机中储存的信息都

顶一下
(0)
0%
踩一下
(0)
0%
------分隔线----------------------------
- 热点内容

-
- centos安装ElasticSearch
CENTOS安装ElasticSearch ElasticSearch 概述 ElasticSearch是一个高可扩展的...
- CentOS7配置默认启动为图形界面
CentOS7配置默认启动为图形界面 一、最直接的方式 修改为默认图...
- apache下网站日志里面显示百度蜘蛛
wdcp后台看的web_log日志里面找了个遍硬是没有找到这些信息 相信...
- DRUID|ORACLE防火墙对连接的影响
虚拟账户产品投产之后,观察到这么一个现象:在无人访问应用...
- centos6.8平台mysql忘记密码后实现
vi /etc/my.cnf 添加行 skip-grant-table service mysqld restart 支持yum安装及...
- centos安装ElasticSearch
- 随机模板
-
-
 织梦dedecms金融投资管理公
人气:2199
织梦dedecms金融投资管理公
人气:2199
-
 韩国SZ服装模板|ecshop服装
人气:670
韩国SZ服装模板|ecshop服装
人气:670
-
 ecshop仿醉品茶叶网模板|绿
人气:1913
ecshop仿醉品茶叶网模板|绿
人气:1913
-
 ecshop成人用品大气模板
人气:1087
ecshop成人用品大气模板
人气:1087
-
 男装网店商城|ecshop韩国
人气:773
男装网店商城|ecshop韩国
人气:773
-
 Amass时尚潮流综合商城ma
人气:102
Amass时尚潮流综合商城ma
人气:102
-