我从来没有建议你尝试在短短10分钟内解决你自己的搜索引擎优化的问题,但它是惊人的你可以做什么,当你被迫要真正使你的时间计数。 我想分享一个共同的搜索引擎优化解决问题,我的10分钟(给予或采取)的过程 – 寻找“失踪”的页面。 你其实可以应用到一系列的问题,其中包括:
找出原因是没有得到一个网页索引 为什么发现网页没有排名 确定如果一个页面受到处罚 合模重复内容的问题
我会休息10分钟下来,每分钟(给予或采取)。 看看接下来的十分钟能做什么吧
0:00-0:30 – 确认该网站索引
总是从头开始-是您的网页确实不见了? 虽然有时得到一个坏名声的准确性(主要是总页数),谷歌的 网站:命令仍是这项工作的最好工具。 这是伟大的潜水深,因为你可以结合它与搜索关键字,“关键字”搜索(精确匹配),和运营商(其他标题:, inurl这样:等)。 当然,最基本的格式就是:

对于这个特殊的工作,总是使用根域。 你永远不知道当谷歌是索引多个子域(或错误的子域),以及该信息后可以派上用场。 当然,现在你只是希望看到谷歌知道你的存在。
0:30-1:00 -确认该网页 的索引
假设谷歌知道您的网站存在,它的时间来检查页面的具体问题。 您可以输入网站的完整路径背后:命令或使用的组合 站点: 和 inurl这样:

如果页面不似乎是谷歌的雷达,通过检测出缩小只是“/文件夹”的问题,看看是否在同一水平上任何事情都可以被索引。 如果页面没有被所有索引,你可以跳过下一步。
1:00-1:30 -确认该网页 的 排名 如果网页被索引的,但你似乎无法找到它在SERP中,拔出一个标记片段的称号并匹配查询(在引号)在谷歌一个确切的。 如果您仍然无法找到它,结合了 网站:example.com 的网页标题或它的一部分了。 如果页面索引而不是排名,你或许可以跳过接下来的几个步骤(跳转到4点标记)。
1:30-2:00 – 对robots.txt的检查 现在,让我们假设你的网站正在部分索引,但在问题的网页从索引中失踪。 虽然在robots.txt的文件中,幸运的是,越来越稀少,但它仍然值得采取快速偷看,以确保你不会意外阻止搜索机器人。 幸运的是,该文件是几乎总是:
http://www.example.com/robots.txt 你要找的是源代码,看起来像这样:
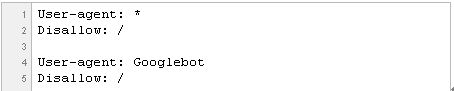
这既可以是一个指令阻止所有用户代理,或只是一个希望Googlebot。 同样,检查任何指示,不让有问题的特定文件夹或网页。
2:00-2:30 – 检查noindex元
另一个意外的阻塞问题可能会出现一个坏noindex元指令。 在HTML源代码(之间的和“)头,你要寻找的是这样的:
虽然这听起来很奇怪有人来阻止他们显然希望索引的网页,坏的META标签和rel =规范(见下文)可以很容易地创建一个坏CMS的设置。
2:30-3:00 – 检查REL的典型
这一个有点棘手。 典型的rel =标记,其本身往往是一件好事,有助于有效地规范化页和删除重复的内容。 标签本身看起来像这样:
问题是当你规范化过于狭窄。 比方说,例如,每一个网站上的网页有一个网址“www.example.com”规范标签 – 谷歌将接受这样的指令折叠整个搜寻指数下跌到只有一个页面。
你为什么要这么做? 你可能不会,故意的,但很容易因为一个严重的CMS或插件出问题。 即使它不是整个网站,很容易过于狭窄和规范化淘汰重要的网页。 这是一个问题,这似乎是在上升。
3:00-4:00 – 检查表头/重定向
在某些情况下,一个页面可能会返回一个坏头例如),(404错误代码,或设计糟糕的重定向(301/302),这是适当的指数化预防。 你需要检查此头-有大量的免费在线(尝试 HTTP的网络嗅探器)。 你在找“200行”的状态代码。 如果您收到重定向串,404,或任何错误代码(4xx或5xx系列),你可以有一个问题。 如果你得到一个重定向(301或302),你发送“丢失”的页面到另一个页面。 原来,这不是真的错过的。
4:00-5:00 – 检查跨站点重复
基本上有两种潜在的重复内容桶 – 重复在您网站的网页和网站之间的重复。 后者可能会发生因与自己的属性共享内容,在法律上重复利用的内容(如联属营销可能这样做),或平刮出来。 问题在于,一旦谷歌会探测这些重复,它可能会挑一,而忽略休息。
如果您怀疑您的“失踪”网页内容已采取的任何其他网站或其他网站采取抢一个独特的冠冕堂皇的句子,它的引号谷歌(做一个精确匹配)。 如果其他网站弹出,您的网页可能已被标记为一式两份。
5:00-7:00 – 内部的重复检查
内部重复通常发生在谷歌抓取同一页的多个网址的变化,例如在网址CGI参数。 如果谷歌达到了两个相同的网页的URL路径,它看到两个独立的页面,其中之一是可能会被忽略。 有时候,这很好,但其他时候,谷歌忽略错误的。
对于内部复制,使用集中的 站点: )查询与中再次引用了一些独特的网页标题的关键字(,无论是独立或使用 标题:。 网址为导向,自然有重复重复的标题和元数据,这样页面的标题是最容易的地方之一,找到它。
7:00-8:00 – 审查锚文本质量
最后两个都有点强硬,更主观的,但我想给一个从哪里开始,如果你怀疑一个页面特有的罚款或贬值几个简单的提示。 很容易发现一个问题是当你有一个可疑的锚文本模式 – 通常,一种罕见的关键字组合,主宰你的外部链接。 这可能来自一个非常积极的(而且通常是低质量)链接建设活动,或像一个小部件的主导你的链接配置文件的东西。
打开网站浏览器 可以让您很轻松地查看你的锚文字笔画广阔。 只要输入您的网址,点击 锚文本分布 (第四选项卡),并选择 短语:
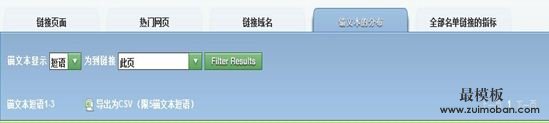
你要寻找的是一种不自然的重复模式。 有些重复是好的 – 你将不得不自然锚文本以您的域名关键字和准确的品牌名称,例如。 比方说,尽管如此,我们70回SEOmoz的链接指向%的锚文本“丹尼佛真棒。” 这将是不自然。如果谷歌认为这是链接建设的操纵的迹象,您可能会看到目标网页处罚。
8:00-10:00 – 审查环节外观质量
链接简介质量是非常主观的,它不是一项任务,你可以做两分钟的正义,但是如果你有一个发挥刑罚,有时会很容易发现一些阴暗的链接很快。 同样,我将使用浏览器打开网站,我将选择以下选项: + 301其次, 只有外部网页, 所有网域网页上的根:

您可以导出到Excel链接,如果你想(深分析大),但现在,只抽查。 只要是对前几页腥,赔率是不错的薄弱环节是一个烂摊子。 通过点击几页,找出来的问题,例如:
可疑的锚文本(无关,垃圾等) 与主题无关的网站疯狂 一个明显的链接嵌入支付或交换块 链接是一个多环节页脚的一部分 其次是广告(不应该)相关链接 此外,寻找任何过分依赖一个低质量链接实物(博客评论,文章营销等)。 虽然完全链接,剖面分析可能需要数小时,但通常非常容易被发现,在短短几分钟内垃圾链接建设。 如果你能发现它的速度快,机会是相当不错的,谷歌可以了。 (10:00) – 时间到 十分钟看起来不是很多(也可能送你那么久只是为了阅读这篇文章),但一旦你建立了一个过程,你可以学到很多有关在短短几分钟的网站很多。 当然,发现问题并解决它是两个完全不同的事情,但我希望这至少给你在一个过程的开始尝试为自己和完善自己的SEO问题,让seo优化不成问题。 (责任编辑:好模板) |
10分钟检查网站页面缺失或错误
时间:2010-11-24 23:08来源: 作者: 点击:次
我从来没有建议你尝试在短短10分钟内解决你自己的搜索引擎优化的问题,但它是惊人的你可以做什么,当你被迫要真正使你的时间计数。 我想分享一个共同的搜索引擎优化解决问题,
顶一下
(1)
100%
踩一下
(0)
0%
------分隔线----------------------------
- 上一篇:做SEO优化何时该用301重定向
- 下一篇:SEOer必须知道的两种重定向方式
- 热点内容

-
- 浅谈口碑营销的利与弊
口碑营销在对中小型企业客户网络营销中,是一种常用的网络推...
- 五个实用的“病毒制造”引爆点
提要:网络营销培训专家归纳了五个比较实用的“病毒制造”的...
- 浅谈做好企业站SEO的3大要点
我们要了解企业站SEO的首要目的是让搜索引擎为企业带来客户,...
- 新网站如何推广自己的品牌
大家好,这是我第二次在A5站长网发布软文,今天我说一下我的...
- 如何在网络社区中利用品牌效应传
这篇文章我们采用的思路是就美国一化妆品品牌做:品牌植入...
- 浅谈口碑营销的利与弊
- 随机模板
-
-
 shopex红色模板
人气:451
shopex红色模板
人气:451
-
 ecshop嘀嗒猫零食商城模板
人气:1037
ecshop嘀嗒猫零食商城模板
人气:1037
-
 ecshop仿kela珂兰钻石整站模
人气:681
ecshop仿kela珂兰钻石整站模
人气:681
-
 ecshop佳品网2012模板
人气:2501
ecshop佳品网2012模板
人气:2501
-
 京东商城360buy模板|ecshop京
人气:1358
京东商城360buy模板|ecshop京
人气:1358
-
 英文绿色衣服外贸商城|
人气:929
英文绿色衣服外贸商城|
人气:929
-